In late 2020 we were teaching a class called embedded systems, which includes a semester assignment, as well. Due to the overall situation in 2020 it was difficult to do it at the university, so we decided to issue the semester assignment as a home work. One of topics of the assignments was the detection of barcode with a neural network. It is not too far fetched to issue such an assignment for a embedded systems class, because we have nowadays available embedded systems which are capable of using neural network, such as the jetson nano from NVIDIA.
The idea we had is to have a camera taking a stream of images and showing it on the display as a video. As soon as an object with a barcode shows up in the scene, the pixels in the area of the barcode are highlighted and the content of the barcode is shown above the area.
Many of the topics in this blog were covered already before, so we might refer here to previous blogs e.g. during the explanation of the published code.
We assigned the students the first task, which was to collect images with barcodes. Each student had to photograph 500 images. They collected them from everywhere, such as from products in grocery stores, kitchens, bathrooms etc. Since we had seven students taking this assignment, we had finally got 3500 images with barcodes.
Labeling
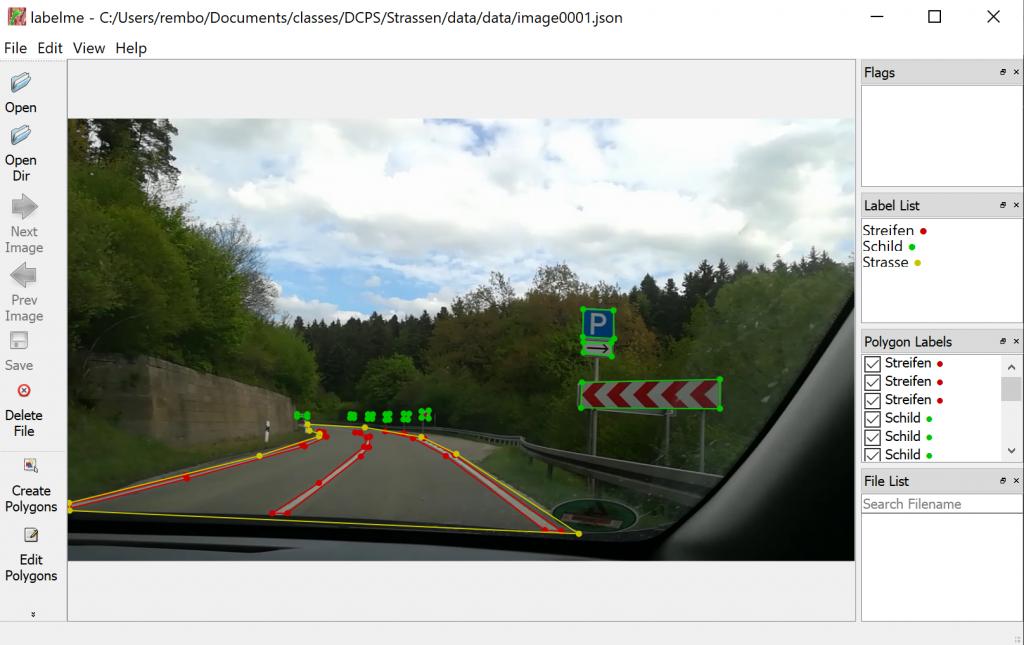
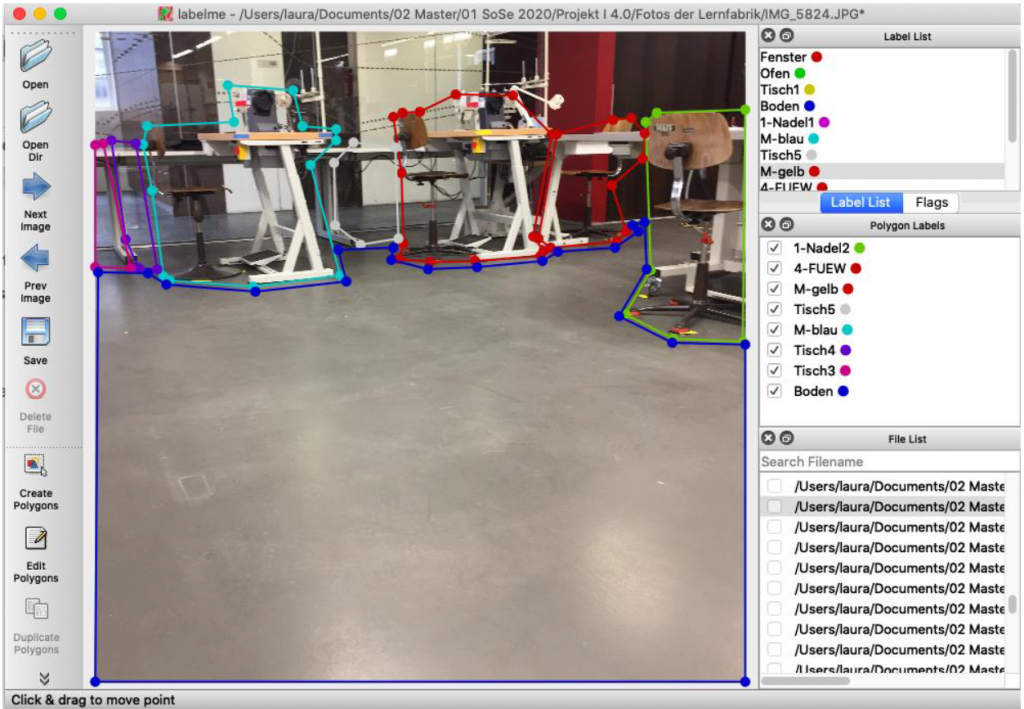
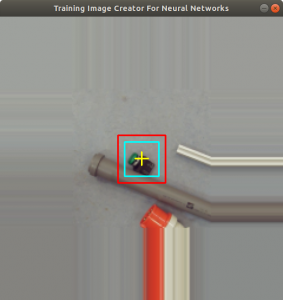
The next task of the assignment was to label the images. The program labelme is an application, where a user can label areas of an image by drawing polygons around objects, see Figure 1. The user can save the labeled image to a json file. The json file contains the complete image in a decoded format and the vertices of the polygons.

The students have done this for each image, so we had 3500 labeled images in json files and we stored them into a directory fullpathdata, see code below. The code defines more global variables which are used throughout this post.
dim = (128, 128) path = r'.../Dokumente/Barcode' dirjson = "train/json" dirimages = "train/images" dirmasks = "train/masks" dirjsonvalid = "valid/json" dirimagesvalid = "valid/images" dirmasksvalid = "valid/masks" dirjsontest = "test/json" dirimagestest = "test/images" dirmaskstest = "test/masks" dirmodels = "models" modelname = "model-bar.h5" modelweightname = "model-bar-check.h5" dirchecks = "checks" dirdata = "data/jsons" fullpathdata = os.path.join(path, dirdata) fullpathjson = os.path.join(path, dirjson) fullpathimages = os.path.join(path, dirimages) fullpathmasks = os.path.join(path, dirmasks) fullpathjsonvalid = os.path.join(path, dirjsonvalid) fullpathimagesvalid = os.path.join(path, dirimagesvalid) fullpathmasksvalid = os.path.join(path, dirmasksvalid) fullpathjsontest = os.path.join(path, dirjsontest) fullpathimagestest = os.path.join(path, dirimagestest) fullpathmaskstest = os.path.join(path, dirmaskstest) fullpathchecks = os.path.join(path, dirchecks)
Data creation
Within the next task we sorted the data into three directories: fullpathjson, fullpathjsonvalid and fullpathjsontest. We decided to use 78% of the json files as training data, 20% as validation data, and the remaining 2% as test data.
The code below iterates through the files in fullpathdata and copies the filenames into the list validlist, testlist and trainlist.
jsonlist = [os.path.join(filename) for filename in os.listdir(fullpathdata) if filename.endswith(".json") ]
shuffle(jsonlist)
num = 20*len(jsonlist) // 100
validlist = jsonlist[:num]
testlist = jsonlist[num:num+num//10]
trainlist = jsonlist[num+num//10:]
Finally the json files are copied into the fullpathjson, fullpathjsonvalid and fullpathjsontest directories, see code below.
for filename in trainlist:
shutil.copy(os.path.join(fullpathdata, filename), os.path.join(fullpathjson, filename))
for filename in validlist:
shutil.copy(os.path.join(fullpathdata, filename), os.path.join(fullpathjsonvalid, filename))
for filename in testlist:
shutil.copy(os.path.join(fullpathdata, filename), os.path.join(fullpathjsontest, filename))
During training, we often figure out, that one of the images is corrupted. It is sometimes hard to see this directly in the error messages of the training processes. For this reason we thought it makes sense to check the data in advance. The function testMasks below is opening the json files, loading in the data, decoding the images and reading in the polygons (“shape”). Each image must have one label, so we confirm this with the assert command. If the assert command fails, the function stops executing, and we remove the json file. It is like sorting out foul fruit.
def testMasks(sourcejsonsdir):
count = 0
directory = sourcejsonsdir
for filename in os.listdir(directory):
if filename.endswith(".json"):
print("{}:{}".format(count,os.path.join(directory, filename)))
f = open(os.path.join(directory, filename))
data = json.load(f)
img_arr = data['imageData']
imgdata = base64.b64decode(img_arr)
img = cv2.imdecode(np.frombuffer(imgdata, dtype=np.uint8), flags=cv2.IMREAD_COLOR)
assert (len(data['shapes']) == 1)
for shape in data['shapes']:
print(shape['label'])
count += 1
f.close()
Below we execute the function testMasks against the directories fullpathjson, fullpathjsonvalid and fullpathjsontest.
testMasks(fullpathjson) testMasks(fullpathjsonvalid) testMasks(fullpathjsontest)
The images taken by the students do not have square shape. For training however we need square shape images with the model we use. The function getRect below extracts a square from the original image and returns four values: the left/upper corner coordinates (ld, lw) and two lengths of the square’s edge (which is the same value). The left/upper corner coordinate is randomly chosen within constraints, and the square’s edge is set to 90% of the actually width or height of the original images. It depends, which is smaller: height or width.
def getRect(img):
width = img.shape[0]
height = img.shape[1]
lw = 0
ld = 0
side = 0
if height > width:
widthscale = int(0.9*width)
left = width - widthscale
lw = randint(0, left)
down = height - widthscale
ld = randint(0, down)
side = widthscale
else:
heightscale = int(0.9*height)
down = height - heightscale
ld = randint(0, down)
left = width - heightscale
lw = randint(0, left)
side = heightscale
return (ld,lw,int(side), int(side))
The function getFrameRGB is a utility function to extract a square image from the original image using the return information from the function getRect. The function getFrameRGB therefore returns a square image from an original image.
def getFrameRGB(img, rect):
retimg = np.zeros((rect[2], rect[3], 3), 'uint8')
assert(rect[2] == rect[3])
retimg[:,:,:] = img[rect[1]:rect[1]+rect[3],rect[0]:rect[0] + rect[2],:]
assert (rect[2] == retimg.shape[0])
assert (rect[2] == retimg.shape[1])
return retimg
The function getFrameGrey is a utility function to extract a greyscale square image from a original image using the return information from the function getRect. It corresponds to the above function, but it is only used for greyscale images. We will later use this function for the masks.
def getFrameGrey(img, rect):
retimg = np.zeros((rect[2], rect[3]), 'uint8')
assert(rect[2] == rect[3])
retimg[:,:] = img[rect[1]:rect[1]+rect[3],rect[0]:rect[0] + rect[2]]
assert (rect[2] == retimg.shape[0])
assert (rect[2] == retimg.shape[1])
return retimg
The above described functions getFrameRGB and getFrameGrey are both used in the function createMasks below. What createMasks basically does is to iterate through a directory containing json files. It opens each json file, decodes the image and stores it in a variable img. Square information is retrieved from img with the functions getRect.
Each json file contains a polygon with its vertices. The vertices are parsed out and a new image mask is generated from them. The image mask is a greyscale image, with pixels containing the 255 value, if they are inside the polygon, and 0 is they are outside the polygon.
Finally we have two images: img_resized and mask_resized which where copied from img and mask.
def createMasks(pre, sourcejsonsdir, destimagesdir, destmasksdir):
assocf = open(os.path.join(path,"assoc_orig.txt"), "w")
count = 0
directory = sourcejsonsdir
for filename in os.listdir(directory):
if filename.endswith(".json"):
print("{}:{}".format(count,os.path.join(directory, filename)))
f = open(os.path.join(directory, filename))
data = json.load(f)
img_arr = data['imageData']
imgdata = base64.b64decode(img_arr)
img = cv2.imdecode(np.frombuffer(imgdata, dtype=np.uint8), flags=cv2.IMREAD_COLOR)
img_resized = img.copy()
rect = getRect(img_resized)
finalmask = np.zeros((img_resized.shape[0], img_resized.shape[1]), 'uint8')
mthresh = np.zeros((img_resized.shape[0], img_resized.shape[1]), 'uint8')
masks=[]
for shape in data['shapes']:
vertices = np.array([[point[1],point[0]] for point in shape['points']])
vertices = vertices.astype(int)
rr, cc = polygon(vertices[:,0], vertices[:,1], img.shape)
mask_orig = np.zeros((img.shape[0], img.shape[1]), 'uint8')
mask_orig[rr,cc] = 255
masks.append(mask_orig)
for m in masks:
_,mthresh = cv2.threshold(m,1,255,cv2.THRESH_BINARY_INV)
finalmask = cv2.bitwise_and(finalmask,finalmask,mask = mthresh)
finalmask += m
img_resized = img.copy()
mask_resized = finalmask.copy()
img_store = cv2.resize(getFrameRGB(img_resized, rect), dim, interpolation = cv2.INTER_AREA)
mask_store = cv2.resize(getFrameGrey(mask_resized, rect), dim, interpolation = cv2.INTER_AREA)
alpha = 0.8 + 0.4*random()
beta = int(random()*15)
img_store = cv2.convertScaleAbs(img_store, alpha=alpha, beta=beta)
cv2.imwrite(os.path.join(destimagesdir, "{}_0_{:05d}.png".format(pre,count)), img_store)
cv2.imwrite(os.path.join(destmasksdir, "{}_0_{:05d}.png".format(pre,count)), mask_store)
img_store = cv2.resize(getFrameRGB(img_resized, rect), dim, interpolation = cv2.INTER_AREA)
mask_store = cv2.resize(getFrameGrey(mask_resized, rect), dim, interpolation = cv2.INTER_AREA)
alpha = 0.8 + 0.4*random()
beta = int(random()*15)
img_store = cv2.convertScaleAbs(img_store, alpha=alpha, beta=beta)
img_store = cv2.rotate(img_store, cv2.ROTATE_90_CLOCKWISE)
mask_store = cv2.rotate(mask_store, cv2.ROTATE_90_CLOCKWISE)
cv2.imwrite(os.path.join(destimagesdir, "{}_90_{:05d}.png".format(pre,count)), img_store)
cv2.imwrite(os.path.join(destmasksdir, "{}_90_{:05d}.png".format(pre,count)), mask_store)
img_store = cv2.resize(getFrameRGB(img_resized, rect), dim, interpolation = cv2.INTER_AREA)
mask_store = cv2.resize(getFrameGrey(mask_resized, rect), dim, interpolation = cv2.INTER_AREA)
alpha = 0.8 + 0.4*random()
beta = int(random()*15)
img_store = cv2.convertScaleAbs(img_store, alpha=alpha, beta=beta)
img_store = cv2.rotate(img_store, cv2.ROTATE_180)
mask_store = cv2.rotate(mask_store, cv2.ROTATE_180)
cv2.imwrite(os.path.join(destimagesdir, "{}_180_{:05d}.png".format(pre,count)), img_store)
cv2.imwrite(os.path.join(destmasksdir, "{}_180_{:05d}.png".format(pre,count)), mask_store)
img_store = cv2.resize(getFrameRGB(img_resized, rect), dim, interpolation = cv2.INTER_AREA)
mask_store = cv2.resize(getFrameGrey(mask_resized, rect), dim, interpolation = cv2.INTER_AREA)
alpha = 0.8 + 0.4*random()
beta = int(random()*15)
img_store = cv2.convertScaleAbs(img_store, alpha=alpha, beta=beta)
img_store = cv2.rotate(img_store, cv2.ROTATE_90_COUNTERCLOCKWISE)
mask_store = cv2.rotate(mask_store, cv2.ROTATE_90_COUNTERCLOCKWISE)
cv2.imwrite(os.path.join(destimagesdir, "{}_270_{:05d}.png".format(pre,count)), img_store)
cv2.imwrite(os.path.join(destmasksdir, "{}_270_{:05d}.png".format(pre,count)), mask_store)
count += 1
else:
continue
f.close()
Now we do data augmentation within createMasks. The function createMasks resizes img_resized and mask_resized and moves the resized images into img_store and mask_store. Both are now square images since createMasks utilizes getRect, getFrameRGB and getFrameGrey. The brightness and the contrast of img_store is randomly changed with the opencv convertScaleAbs method. Then a rotation is applied to the image.
This is done four times. So createMasks creates for each input image, four rotated output images with randomized brightness and contrast and saves them into a directory.
createMasks("train", fullpathjson, fullpathimages, fullpathmasks)
createMasks("valid", fullpathjsonvalid, fullpathimagesvalid, fullpathmasksvalid)
createMasks("test", fullpathjsontest, fullpathimagestest, fullpathmaskstest)
In the above code you see how createMasks is applied to the images inside the train, validation and test directories. The output images are stored in fullpathimage, fullpathimagevalid and fullpathimagetest directories and the output masks into fullpathmasks, fullpathmasksvalid and fullpathmaskstest directories. Since we have originally 3500 images, the code above produces due to data augmentation 3500 times 4 images, which is 14000.
Training
We generated the model for training with get_unet (see below), which was written by Tobias Sterbak. The original code can be found here. Few modification have been done, which is basically one of the last lines:
c10 = Conv2D(2, (1, 1), activation=”softmax”) (c9)
The output of the model therefore will be a two layer image, which represents a mask indicating the barcode of an input image. Pixels of the first layers indicate a barcode if set to 1, and pixels of the second layer indicate no barcode if set to 1. The code will not be explained any further, so we refer to the original code.
def conv2d_block(input_tensor, n_filters, kernel_size=3, batchnorm=True):
# first layer
x = Conv2D(filters=n_filters, kernel_size=(kernel_size, kernel_size), kernel_initializer="he_normal",
padding="same")(input_tensor)
if batchnorm:
x = BatchNormalization()(x)
x = Activation("relu")(x)
# second layer
x = Conv2D(filters=n_filters, kernel_size=(kernel_size, kernel_size), kernel_initializer="he_normal",
padding="same")(x)
if batchnorm:
x = BatchNormalization()(x)
x = Activation("relu")(x)
return x
def get_unet(input_img, n_filters=16, dropout=0.5, batchnorm=True):
# contracting path
c1 = conv2d_block(input_img, n_filters=n_filters*1, kernel_size=3, batchnorm=batchnorm)
p1 = MaxPooling2D((2, 2)) (c1)
p1 = Dropout(dropout*0.5)(p1)
c2 = conv2d_block(p1, n_filters=n_filters*2, kernel_size=3, batchnorm=batchnorm)
p2 = MaxPooling2D((2, 2)) (c2)
p2 = Dropout(dropout)(p2)
c3 = conv2d_block(p2, n_filters=n_filters*4, kernel_size=3, batchnorm=batchnorm)
p3 = MaxPooling2D((2, 2)) (c3)
p3 = Dropout(dropout)(p3)
c4 = conv2d_block(p3, n_filters=n_filters*8, kernel_size=3, batchnorm=batchnorm)
p4 = MaxPooling2D(pool_size=(2, 2)) (c4)
p4 = Dropout(dropout)(p4)
c5 = conv2d_block(p4, n_filters=n_filters*16, kernel_size=3, batchnorm=batchnorm)
# expansive path
u6 = Conv2DTranspose(n_filters*8, (3, 3), strides=(2, 2), padding='same') (c5)
u6 = concatenate([u6, c4])
u6 = Dropout(dropout)(u6)
c6 = conv2d_block(u6, n_filters=n_filters*8, kernel_size=3, batchnorm=batchnorm)
u7 = Conv2DTranspose(n_filters*4, (3, 3), strides=(2, 2), padding='same') (c6)
u7 = concatenate([u7, c3])
u7 = Dropout(dropout)(u7)
c7 = conv2d_block(u7, n_filters=n_filters*4, kernel_size=3, batchnorm=batchnorm)
u8 = Conv2DTranspose(n_filters*2, (3, 3), strides=(2, 2), padding='same') (c7)
u8 = concatenate([u8, c2])
u8 = Dropout(dropout)(u8)
c8 = conv2d_block(u8, n_filters=n_filters*2, kernel_size=3, batchnorm=batchnorm)
u9 = Conv2DTranspose(n_filters*1, (3, 3), strides=(2, 2), padding='same') (c8)
u9 = concatenate([u9, c1], axis=3)
u9 = Dropout(dropout)(u9)
c9 = conv2d_block(u9, n_filters=n_filters*1, kernel_size=3, batchnorm=batchnorm)
c10 = Conv2D(2, (1, 1), activation="softmax") (c9)
model = Model(inputs=[input_img], outputs=[c10])
return model
Below you see the code of the data generator used during training. The computer will not be able to load 14000 images into memory, so we have to use batches. The function generatebatchdata delivers batches of training data for the training process. Note that generatebatchdata additionally randomizes the brightness and contrast of 70% of the training images to augment the data further. The code was described in previous posts, so we will omit any more description.
def generatebatchdata(batchsize, fullpathimages, fullpathmasks):
imagenames = os.listdir(fullpathimages)
imagenames.sort()
masknames = os.listdir(fullpathmasks)
masknames.sort()
for i in range(len(imagenames)):
assert(imagenames[i] == masknames[i])
while True:
batchstart = 0
batchend = batchsize
while batchstart < len(imagenames):
imagelist = []
masklist = []
limit = min(batchend, len(imagenames))
for i in range(batchstart, limit):
if imagenames[i].endswith(".png"):
img = cv2.imread(os.path.join(fullpathimages,imagenames[i]),cv2.IMREAD_COLOR )
if random.random() > 0.3:
alpha = 0.8 + 0.4*random.random();
beta = int(random.random()*15)
img = cv2.convertScaleAbs(img, alpha=alpha, beta=beta)
imagelist.append(img)
if masknames[i].endswith(".png"):
img0 = np.zeros(dim, 'uint8')
img1 = np.zeros(dim, 'uint8')
img0 = cv2.imread(os.path.join(fullpathmasks,masknames[i]),cv2.IMREAD_UNCHANGED)
img0 = np.where(img0 > 0, 1, 0)
img1 = np.where(img0 > 0, 0, 1)
img = np.zeros((dim[0], dim[1], 2),'uint8')
msum = np.sum(np.array(img0) + np.array(img1))
assert(msum == dim[0]*dim[1])
img[:,:,0] = img0[:,:]
img[:,:,1] = img1[:,:]
masklist.append(img)
train_data = np.array(imagelist, dtype=np.float32)
train_mask= np.array(masklist, dtype=np.float32)
train_data -= train_data.mean()
train_data /= train_data.std()
yield (train_data,train_mask)
batchstart += batchsize
batchend += batchsize
We decided to use a batch size of ten for model training. The input layer is instantiated and assigned to input_img. The function get_unet creates the model and the model is compiled.
We use predefined callback functions for training, such as early stopping. The callback function were described in previous posts as well.
The variables stepstrainimages and stepsvalidimages are needed for the fit method to set its parameters steps_to_epoch and validation_steps, see code below.
batchsize = 10
input_img = Input((dim[0], dim[1], 3), name='img')
model = get_unet(input_img, n_filters=1, dropout=0.0, batchnorm=True)
model.compile(optimizer=Adam(), loss="categorical_crossentropy", metrics=["accuracy"])
#model.load_weights(os.path.join(path, dirmodels,modelname))
callbacks = [
EarlyStopping(patience=10, verbose=1),
ReduceLROnPlateau(factor=0.1, patience=3, min_lr=0.00001, verbose=1),
ModelCheckpoint(os.path.join(fullpathmodels,modelweightname), verbose=1, save_best_only=True, save_weights_only=True)
]
stepstrainimages = len(os.listdir(fullpathimages))//batchsize
stepsvalidimages = len(os.listdir(fullpathimagesvalid))//batchsize
Below you find the code to instantiate the data generators for training and validation and the fit function to train the model. Number of epochs were set to 20, but the code below can be executed several times in a row (especially if you use a jupyter editor). After training, the model’s weights (modelname) and the model structure (modelnamejson) are saved.
generator_train = generatebatchdata(batchsize, fullpathimages, fullpathmasks)
generator_valid = generatebatchdata(batchsize, fullpathimagesvalid, fullpathmasksvalid)
model.fit(generator_train,steps_per_epoch=stepstrainimages, epochs=20, callbacks=callbacks, validation_data=generator_valid, validation_steps=stepsvalidimages)
model.save_weights(os.path.join(path, dirmodels,modelname))
json_model = model.to_json()
with open(os.path.join(path, dirmodels,modelnamejson), "w") as json_file:
json_file.write(json_model)
For testing the model, we use the code below. It loads all test images into memory. Since there are only a limited number, it will not face a memory problem to store them into an array. The images are further processed by standardizing with the mean and the standard deviation.
imagetestlist = []
imagetestnames = os.listdir(fullpathimagestest)
imagetestnames.sort()
for imagename in imagetestnames:
if imagename.endswith(".png"):
imagetestlist.append(cv2.imread(os.path.join(fullpathimagestest,imagename),cv2.IMREAD_COLOR ))
test_data = np.array(imagetestlist, dtype=np.float32)
test_data -= test_data.mean()
test_data /= test_data.std()
predictions = model.predict(test_data, batch_size=1, verbose=1)
The predict method above predicts the test images and returns the result into the predictions variable.
Below you find the code to lift the pixel values to 255 in case the predicted images pixel above 0.5.
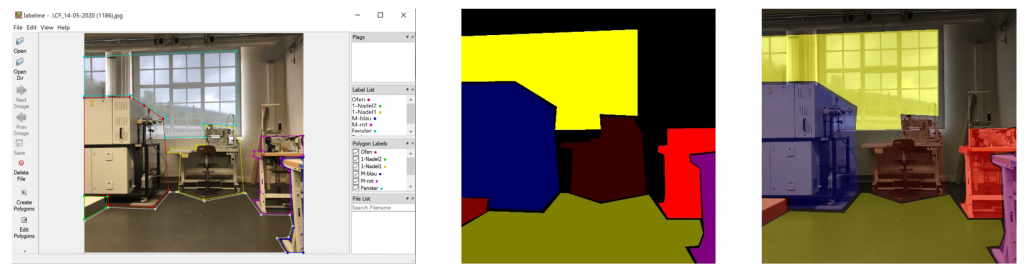
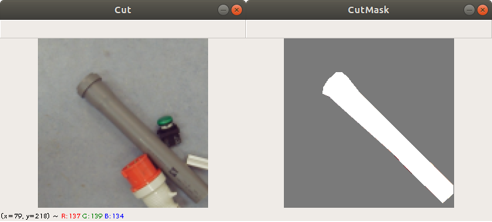
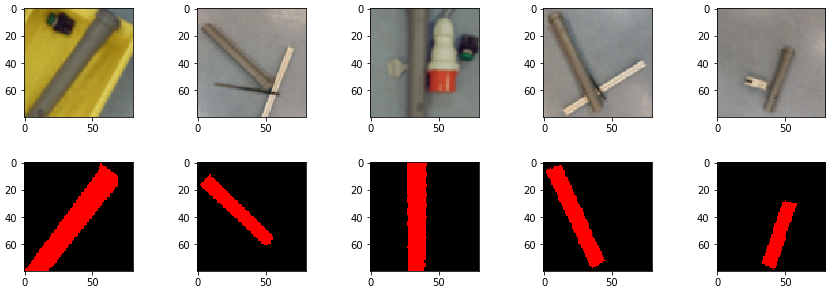
ind = 56 plt.imshow(imagetestlist[ind]) img = predictions[ind][:,:,0] img = np.where(img > 0.5, 255, 0) plt.imshow(img)
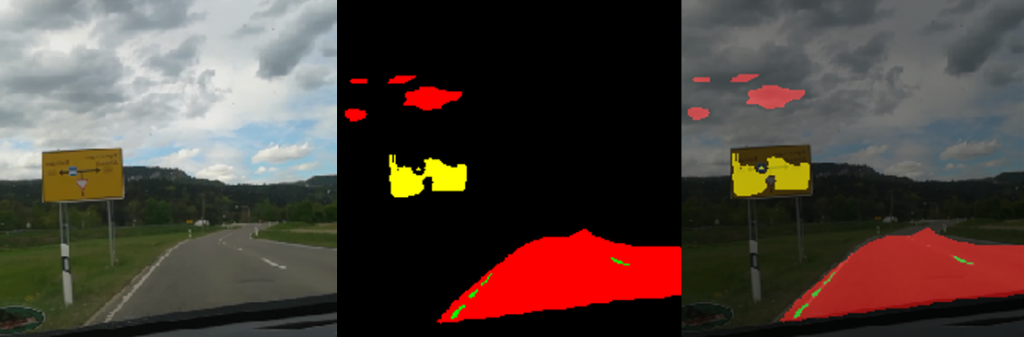
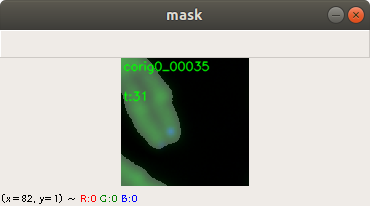
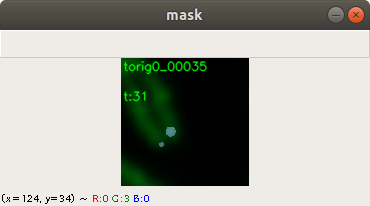
Figure 2 shows two images. The first image on the left side is the original image and the second image on the right side is the predicted mask image. You can see that the mask image is clearly showing the location of the pixels indicating a barcode.

Life Example
The idea of this project was to use a life video stream and apply the predict function on the images of the video stream to generate masks. The masks can be overlaid with the original images and shown on the display.
Another idea is to apply a barcode scanning software to the original image to read the barcode’s content. The content is then put as text onto the display.
Below we first open the model structure and save it into json_file. The function model_from_json moves the structure into loaded_model. The code then sets the weights, stored in modelname into loaded_model.
json_file = open(os.path.join(fullpathmodels, modelnamejson), 'r') loaded_model_json = json_file.read() json_file.close() loaded_model = model_from_json(loaded_model_json) loaded_model.load_weights(os.path.join(path, dirmodels,modelname))
The images of the video stream do not have square size, so we need to extract square images from them. For this we have written the function getRectStatic. It is basically does the as same function getRect, but the randomization of the image position coordinates was taken out.
def getRectStatic(img):
width = img.shape[0]
height = img.shape[1]
lw = 0
ld = 0
side = 0
if height > width:
widthscale = int(0.9*width)
left = width - widthscale
lw = left//2
down = height - widthscale
ld = down//2
side = widthscale
else:
heightscale = int(0.9*height)
down = height - heightscale
ld = down//2
left = width - heightscale
lw = left//2
side = heightscale
return (ld,lw,int(side), int(side))
Below the code which displays a overlaid image from a webcam with the predicted mask image. The opencv method VideoCapture instantiates a video stream object. Inside the endless while loop, an image is read from the video stream. The image is then applied to getRectStatic to extract coordinates of a square image. The square image img is retrieved then from frame. The image img is resized and moved into a one element imgpredict list. This element inside imgpredict is then standardized with the mean and standard deviation method.
The keras method predict processes imgpredict and moves the predicted output (one mask image) into a one element predictions list. The numpy where method sets each pixel value of the mask image to 255 or to 0, depending if the value is above 0.3 or below.
The code below resizes the mask image and gets the largest contour of mask image with opencv method findContours. The contour is used to compute a rectangle around the contour (minAreaRect) and to draw it on the display (drawContour).
The function decode is a pyzbar library function. It calculates from a barcode image the content of the barcode and returns it into the variable result. The code is iterating through the structure of the variable result and moves the recognized barcode content into barcodetext. The string in barcodetext is put onto the display as well.
vid = cv2.VideoCapture(0)
saveimg = np.zeros((dim[0], dim[1], 3), "uint8")
count = 0
bardcodetxt = ""
while(True):
ret, frame = vid.read()
d,w,side,_ = getRectStatic(frame)
img = np.zeros((side, side, 3), "uint8")
img[::] = frame[w:w+side, d:d+side,:]
imgpredict = []
imgpredict.append(cv2.resize(img, dim, interpolation = cv2.INTER_AREA))
imgpredict = np.array(imgpredict, dtype=np.float32)
imgpredict -= imgpredict.mean()
imgpredict /= imgpredict.std()
predictions = loaded_model.predict(imgpredict, batch_size=1, verbose=0)
prediction = predictions[0][:,:,0]
prediction = np.where(prediction > 0.3, 255, 0)
prediction = np.array(prediction, "uint8")
predresized = np.zeros((side, side, 3), np.uint8)
predresized[:,:,2] = cv2.resize(prediction, (side, side), interpolation = cv2.INTER_AREA)[:,:]
contours, hierarchy = cv2.findContours(prediction,cv2.RETR_TREE,cv2.CHAIN_APPROX_SIMPLE)
cnts = sorted(contours, key=cv2.contourArea)
result = decode(img)
if len(cnts) > 0:
rect = cv2.minAreaRect(cnts[-1])
box = cv2.boxPoints(rect)
box *= side/dim[0]
box = np.int0(box)
img = cv2.drawContours(img,[box],0,(0,255,0),2)
for index,i in enumerate(result):
bardcodetxt=i.data.decode("utf-8")
saveimg = newimg.copy()
newimg = cv2.addWeighted(img, 0.5, predresized, 0.5, 0)
newimg = cv2.putText(newimg, bardcodetxt, (20,30), cv2.FONT_HERSHEY_SIMPLEX, 1, (255,255,255), 2, cv2.LINE_AA)
cv2.imshow('frame',newimg)
key = cv2.waitKey(1) & 0xFF
if key == ord('q'):
break
if key == ord('s'):
cv2.imwrite(os.path.join(fullpathimagestest, f"{count}.png"), cv2.resize(img, dim, interpolation = cv2.INTER_AREA))
count += 1
vid.release()
cv2.destroyAllWindows()
Results
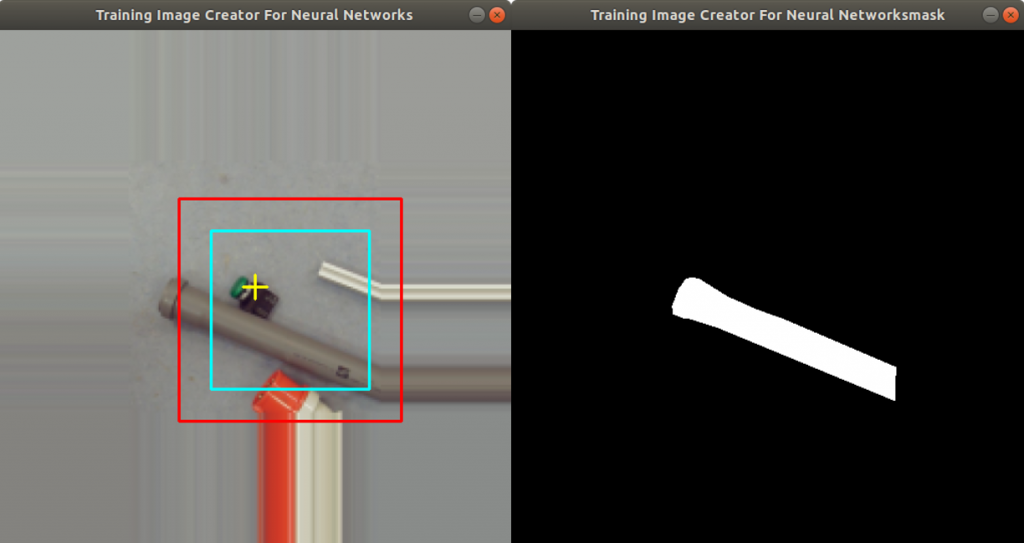
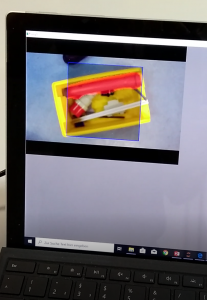
In Figure 3 you find a screen shot of the displayed video stream. Here somebody holds a bottle with barcode into the scene of the webcam. The predicted mask of the barcode is overlaid to the original video stream. You find the rectangle around the mask (green). On the above and left corner you can find the content of the barcode computed by the pyzbar library.

The life video stream works actually pretty good. It does show the position of barcodes, whenever you put one in front of the webcam. The barcode reading software (pyzbar) however needs several retries to compute the content of the barcode correctly. In general we can say that neural networks can be used very well for determining the barcode position.
Acknowledgement
Thank you very much to the master students of the class embedded systems of winter semester 2020. Seven students labeled in their semester assignment 3500 images which is very time consuming work.
Also special thanks to the University of Applied Science Albstadt-Sigmaringen for providing the infrastructure and the appliances to enable this class.