here we want to show our achievements and fails with deep reinforcement learning. The paper [1] describes an algorithm for training atari games such as the game breakout. Standford university tought this algorithm in its deep learning class lecture 14 reinforcement learning. Since the results looked pretty promising we tried to recreate the methods with our own implementations. We decided to try it with another game which is the snake game. Here the player controls a snake with four action keys (RIGHT, LEFT, UP, DOWN) moving on the screen. The player has to control the snake in a way it eats food and he has to avoid the frame’s borders otherwise the snake dies, see Picture 1 how the snake is going to die. In case it runs out the frame’s border the game terminates. Each time the snake eats food, the body length of the snake is increased. During the game the player has also to avoid the snake’s body otherwise the game terminates, as well.
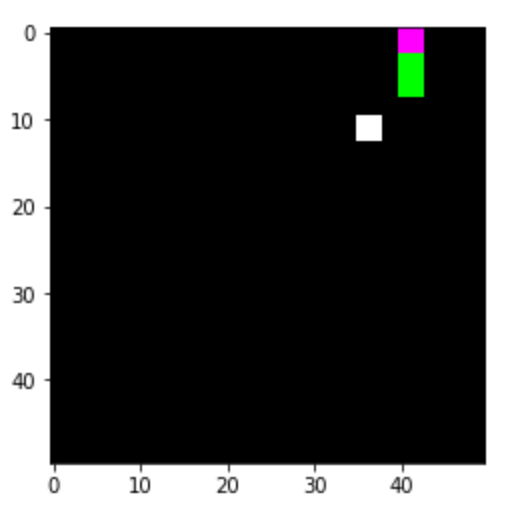
Picture 2 shows how the snake is moving from one position to the next towards the food (white box). The snake game we used has been created by Rajat Biswas and can be downloaded from here. However to access the images of the game and the action keys, we had to modify the code, which is copied into this post. Modifications had been very substantial so the code might not be recognizable anymore with exception of some variable names.

Basic Setups
In the beginning we tried a frame size of 100×100 for each image. We soon figured out that the graphics card reached its capacity and the computer crashed. The authors of the paper [1] used frame sizes of 84×84, however we then tried with 50×50 because of our failing experiences. The objects of the game (snake, food) displayed in the images were still recognizable after resizing to 50×50, so we kept this frame size, see dim in the code below.
The snake in Rajat’s game was drawn in color green. Here is now the problem: Reinforcement Learning is based on the theory of Markov Decision Process (MDP). In MDP we are dealing with states, and the state tells you what action you going to do for the future. Only the current state is relevant, but not the past states. So if you take a look at the snake game, Picture 1, you find that we have drawn the snake’s head in color magenta (R: 255, G: 0, B:255). Now you always know as player where the head and where the tail of the snake is by just looking at one image. In the original game the creator colored the complete snake in green. In the atari game example [1] the authors faces the problem with not knowing from which direction the flying ball was coming. They solved it by capturing four sequential images and adding their grayscale images into the layers of a new image. Now they were able to see the dynamics of a flying ball.
A good lecture in Markov Decision Process can be found here. Actually it is very recommend to take a look into MDP theory before programming anything in reinforcement learning, otherwise it will be hard to understand the programming.
The code below shows some necessary directories, such as the data directory containing a large sample of images of the game (also called replay memory), the model directory, containing the model’s checkpoint with the name modelweightname.
Rajat’s game used the string identifiers RIGHT, LEFT, UP DOWN to indicate a keystroke. The dictionaries actionstonum and numtoactions convert the string identifiers to numbers, and vice versa.
dim = (50,50)
pathname = r"/home/inf/Dokumente/Reinforcement"
datadirname = "data"
validdirname = "valid"
modeldirname = "model"
datacsvname = "data.csv"
modeljsonname="model-regr.json"
modelweightname="model-regr.h5"
actionstonum = {"RIGHT": 0,
"LEFT": 1,
"UP" : 2,
"DOWN" : 3,
}
numtoactions = {0: "RIGHT",
1: "LEFT",
2: "UP",
3: "DOWN",
}
The Model
The model comes originally from [1], however we copied it from the kera’s reinforcement website, because the author’s did not describe the model thoroughly enough to be able to reconstruct it. The function code create_q_model is copied in the code section below. It consists of five neural network layers. Three convolution layers and two fully connected layers. The last layer is a fully connected layer with four outputs. Each output represents one Q state of one action from the action space RIGHT, LEFT, UP DOWN.
A Q state is a variable, which tells us how much food the snake will eat in future, if a certain action is taken. Eating food will give in our programming the player a reward of one. An Example: we assume the Q state for action RIGHT is two. This means, if the player chooses for action RIGHT, the prediction is that the player eats food two more times.
def create_q_model():
inputs = layers.Input(shape=(dim[0], dim[1], 3,))
layer1 = layers.Conv2D(32, 8, strides=4, activation="relu")(inputs)
layer2 = layers.Conv2D(64, 4, strides=2, activation="relu")(layer1)
layer3 = layers.Conv2D(64, 3, strides=1, activation="relu")(layer2)
layer4 = layers.Flatten()(layer3)
layer5 = layers.Dense(512, activation="relu")(layer4)
action = layers.Dense(4, activation="linear")(layer5)
return keras.Model(inputs=inputs, outputs=action)
Breaking down the code
We have written the main code in class Game, where we incorporated Rajat’s code. By now his code is probably very hard to recognize. The class Game became pretty huge, so we need to break it down. Below you see the class definition, the constructor __init__ and the method initialize.
The constructor sets the frame size of the game to 200×200. Later, frame images are resized to 50×50. The game needs four colors: back, white, green and magenta. the variables imgresh1 and imgresh2 are two sequential images of the game, e.g. two images in Picture 2. The first image is taken before the player takes an actions and the second image is taken after the player takes action. Basically these two images represent the current state and the future state. The constants MAXREWARD is assigned to reward the player as soon as the snake eats food. The program assigns PENALTY to penalize the player when the snake hits the border or its own body. If an action just moves the snake, then MOVEPENALTY is assigned to reward. We actually have set this to zero, so it has no effect.
We have set the BATCHSIZE of training data to 20. Below it shows actually the number 19, but a one data is added during training which makes it to 20.
DISCOUNT, ALPHA and EPSILON are values of the Bellman equation. This is part of the MDP theory, so we skip to explain it. The MDP lecture is really recommended to study here. REPLAYSIZE is also explained in [1], so we took the concept from there. It is a maximum number for storing current and future images in a replay memory. So the code here stores 40.000 current and future images on disk and uses the images to retrain the model. Two models are created with the create_q_model function: model and model_target. model is the current model, and model_target is the future model. The current model is retrained all the time during the game, and the future model is updated once after playing numerous games. We use the Adam optimizer and the loss function Huber. Huber is a combination of a square function and a absolute function. It punishes huge differences less than a square function. The remaining important code in the constructor is the loading the weights to model_target.
The method initialize initializes the pygame environment, which is part of the library we used in the code. Here the clock is set, and the frame size is set to 200×200. The first positions of the snake (snake_pos) and the food (food_pos) are randomly set. The variable changeto holds the current action (RIGHT, LEFT, UP DOWN) hit by the player. The variable direction holds mostly the same value as changeto. However, in some cases it does not. E.g. if the snake runs right, the player hits left, so the snake continues to run right. This means that changeto holds now the value left, but direction the value right. The method initialize completes with loading the weights into the current model model.
class Game:
def __init__(self, lr=1e-3, checkpointparname=modelweightname):
self.speed = 80
self.frame_size_x = 200
self.frame_size_y = 200
self.black = pygame.Color(0, 0, 0)
self.white = pygame.Color(255, 255, 255)
self.green = pygame.Color(0, 255, 0)
self.mag = pygame.Color(255, 0, 255)
self.imgresh1 = None
self.imgresh2 = None
self.reward = 0
self.MAXREWARD = 1.0
self.PENALTY = -1.0
self.MOVEPENALTY = 0.0
self.BATCHSIZE = 19
self.DISCOUNT = 0.99
self.ALPHA = 0.3
if manual == True:
self.EPSILON = 0.999
else:
self.EPSILON = 0.3
self.REPLAYSIZE = 40_000
self.overall_score = 0
self.overall_numbatches = 0
self.model = create_q_model()
self.model_target = create_q_model()
self.learningrate = lr
self.optimizer = keras.optimizers.Adam(learning_rate=self.learningrate, clipnorm=1.0)
self.loss_function = keras.losses.Huber()
self.checkpointname = os.path.join(pathname, modeldirname,checkpointparname)
print(f"loading checkpoint: {self.checkpointname}")
self.model_target.load_weights(self.checkpointname)
self.overall_scores=[]
self.checkpoint_counter=0
self.shufflelist = []
def initialize(self, i, j):
status = pygame.init()
if status[1] > 0:
print(f'Number of Errors: {status[1]} ...')
sys.exit(-1)
pygame.display.set_caption(f"{i}-{j}")
self.game_window = pygame.display.set_mode((self.frame_size_x, self.frame_size_y))
self.controller = pygame.time.Clock()
posx = (random.randint(40,160)//10)*10
posy = (random.randint(40,160)//10)*10
self.snake_pos = [posx, posy]
self.snake_body = [[posx, posy], [posx-10, posy], [posx-(2*10), posy]]
self.food_pos = [random.randrange(1, (self.frame_size_x//10)) * 10, random.randrange(1, (self.frame_size_y//10)) * 10]
self.food_spawn = True
self.direction = 'RIGHT'
self.changeto = self.direction
self.score = 0
self.numbatches = 0
self.event_happened = False
self.model.load_weights(self.checkpointname)
The code below shows the methods run, get_maxi, game_over and get_direction of the class Game.
The method run executes one iteration of the snake game. This means run draws the current image, checks for a key stroke, updates the graphical objects such as snake head, snake body and food and draws the next image. While executing run, the images are saved to disk with a unique number for identification. To prevent overwriting images, the method get_maxi reads the maximum identification number and sets a counter i to it.
In the beginning the method run saves the first image of the game window to the opencv image imgresh1. We use the numpy method frombuffer and reshape for retrieving the image and the opencv method resize to lower the image size to 50×50. The image imgresh1 is then moved into the neural network to get a prediction of the four Q states with model. The maximum of the four Q states (tensorflow method argmax) gives you the predicted action. It must be a number between zero and three. This is also part of the Bellman equation from the MDP theory.
The run method reads the key strokes and moves the information into the attribute changeto. With the help of the constant EPSILON, we bring some variation between prediction, randomness or direction into the game. If the constant EPSILON is close to one, then the run method is rather on the prediction side (Exploitation). If the constant EPSILON is close to zero, then the method run is rather of the randomness/direction side (Exploration). Direction is given by the method get_direction. Again, the constant EPSILON is also part of the MDP theory.
As mentioned above, changeto is an attribute telling you in which direction the player wants to move the snake. However if e.g. the snake moves right, and player strikes the left key, then the snake should still move right. For this we need the attribute direction. It tells the actual direction of the snake independent of the key stroke.
The method run is then checking if the snake has eaten the food. If yes, a new food position is drawn and the attribute reward is set to MAXREWARD and the body of the snake is enlarged. If no food or no border has been hit, than the attribute reward is set to MOVEPENALTY. In case the snake hits the border or hits its own body, then the attribute reward is set to PENALTY. This is done in the method game_over.
Finally the snake is redrawn and an image of the game window is moved into imgresh2. The images imgresh1 and imgresh2 form the current state and the future state.
At the end, the method run retrains the model with the method train. We are doing this only with every fourth current state and future state. We are doing this to emphasize more the scoring and the terminations and to de-emphasize the moving.
If the snake hits the border, the method game_over is executed and it terminates the method run. Here the model is retrained as well with the current state (imgresh1), future state (imgresh2), action taken (changeto), reward (reward) and the termination information.
class Game:
# constructur and initializer, see above
def run(self, i_index):
i = i_index + self.get_maxi() + 1
j = 0
while True:
img1 = np.frombuffer(pygame.image.tostring(self.game_window, "RGB"), dtype=np.uint8)
self.imgresh1 = np.reshape(img1,(self.frame_size_x,self.frame_size_y, 3))
self.imgresh1 = cv2.resize(self.imgresh1, dim, interpolation = cv2.INTER_NEAREST )
current_state = np.array(self.imgresh1, dtype=np.float32)/255.0
state_tensor = tf.convert_to_tensor(current_state)
state_tensor = tf.expand_dims(state_tensor, 0)
action_probs = self.model(state_tensor, training=False)
theaction = tf.argmax(action_probs[0]).numpy()
for event in pygame.event.get():
if event.type == pygame.QUIT:
pygame.quit()
return
# Whenever a key is pressed down
elif event.type == pygame.KEYDOWN:
if event.key == pygame.K_UP or event.key == ord('w'):
self.changeto = 'UP'
if event.key == pygame.K_DOWN or event.key == ord('s'):
self.changeto = 'DOWN'
if event.key == pygame.K_LEFT or event.key == ord('a'):
self.changeto = 'LEFT'
if event.key == pygame.K_RIGHT or event.key == ord('d'):
self.changeto = 'RIGHT'
# Esc -> Create event to quit the game
if event.key == pygame.K_ESCAPE:
pygame.event.post(pygame.event.Event(pygame.QUIT))
if np.random.random() > self.EPSILON:
self.changeto = numtoactions[theaction]
else:
if manual != True:
#self.changeto = numtoactions[np.random.randint(0, len(actionstonum))]
self.changeto = self.get_direction();
if self.changeto == 'UP' and self.direction != 'DOWN':
self.direction = 'UP'
if self.changeto == 'DOWN' and self.direction != 'UP':
self.direction = 'DOWN'
if self.changeto == 'LEFT' and self.direction != 'RIGHT':
self.direction = 'LEFT'
if self.changeto == 'RIGHT' and self.direction != 'LEFT':
self.direction = 'RIGHT'
if self.direction == 'UP':
self.snake_pos[1] -= 10
if self.direction == 'DOWN':
self.snake_pos[1] += 10
if self.direction == 'LEFT':
self.snake_pos[0] -= 10
if self.direction == 'RIGHT':
self.snake_pos[0] += 10
self.snake_body.insert(0, list(self.snake_pos))
if self.snake_pos[0] == self.food_pos[0] and self.snake_pos[1] == self.food_pos[1]:
self.score += 1
self.reward = self.MAXREWARD
self.food_spawn = False
else:
self.snake_body.pop()
self.reward = self.MOVEPENALTY
if not self.food_spawn:
self.food_pos = [random.randrange(1, (self.frame_size_x//10)) * 10, random.randrange(1, (self.frame_size_y//10)) * 10]
self.food_spawn = True
self.game_window.fill(self.black)
n = 0
for pos in self.snake_body:
if n == 0:
pygame.draw.rect(self.game_window, self.mag, pygame.Rect(pos[0], pos[1], 10, 10))
else:
pygame.draw.rect(self.game_window, self.green, pygame.Rect(pos[0], pos[1], 10, 10))
n=+1
pygame.draw.rect(self.game_window, self.white, pygame.Rect(self.food_pos[0], self.food_pos[1], 10, 10))
if self.snake_pos[0] < 0 or self.snake_pos[0] > self.frame_size_x-10:
self.game_over(i,j)
return
if self.snake_pos[1] < 0 or self.snake_pos[1] > self.frame_size_y-10:
self.game_over(i,j)
return
for block in self.snake_body[1:]:
if self.snake_pos[0] == block[0] and self.snake_pos[1] == block[1]:
self.game_over(i,j)
return
pygame.display.update()
img2 = np.frombuffer(pygame.image.tostring(self.game_window, "RGB"), dtype=np.uint8)
self.imgresh2 = np.reshape(img2,(self.frame_size_x,self.frame_size_y, 3))
self.imgresh2 = cv2.resize(self.imgresh2, dim, interpolation = cv2.INTER_NEAREST )
self.controller.tick(self.speed)
if j > 0:
if self.reward == self.MAXREWARD:
self.train(i,j, False)
elif j%4 == 0:
self.train(i,j, False)
j += 1
def game_over(self,i,j):
self.reward = self.PENALTY
img2 = np.frombuffer(pygame.image.tostring(self.game_window, "RGB"), dtype=np.uint8)
self.imgresh2 = np.reshape(img2,(self.frame_size_x,self.frame_size_y, 3))
self.imgresh2 = cv2.resize(self.imgresh2, dim, interpolation = cv2.INTER_NEAREST )
self.train(i,j, True)
self.overall_score += self.score
self.game_window.fill(self.black)
pygame.display.flip()
pygame.quit()
def get_maxi(self):
maxi = 0
for item in self.shufflelist:
curr = item[0]
s = re.findall(r'\d+', curr)[0]
if int(s) > maxi:
maxi = int(s)
return maxi
def get_direction(self):
x = self.snake_pos[0] - self.food_pos[0]
x1 = self.snake_body[1][0] - self.food_pos[0]
y = self.snake_pos[1] - self.food_pos[1]
y1 = self.snake_body[1][1] - self.food_pos[1]
direction = None
direction_h = None
direction_v = None
if x > 0:
direction_h = 'LEFT'
else:
direction_h = 'RIGHT'
if y > 0:
direction_v = 'UP'
else:
direction_v = 'DOWN'
if abs(x) > abs(y):
direction = direction_h
if y == y1 and (abs(x) > abs(x1)):
#print(f" hit v x: {abs(x)} x1: {abs(x1)} y: {y} y1: {y1}")
direction = direction_v
else:
direction = direction_v
if x == x1 and (abs(y) > abs(y1)):
#print(f" hit h x: {abs(y)} x1: {abs(y1)} y: {x} y1: {x1}")
direction = direction_h
return direction
The code below shows again the class Game, however without the methods run, game_over, get_direction and get_maxi, which were described above.
In the code below we implemented the methods from the description in [1] and from the deep reinforcement theory. In [1] the authors suggested a replay memory to avoid similarities of current states within a batch of training data. Their argument was, that this can cause feedback loops which are bad for convergence.
Game’s method load_replay_memory loads in all current states (currentpicname), actions (action), future states (nextpicname) and termination information into the list shufflelist. The list shufflelist is then randomly reordered. It represents now the replay memory.
The method save_replay_memory saves a pandas datasheet (datacsvname) to disk with all information to reload shufflelist at another time again.
The method pop_batch picks the first set of entries from the replay memory. Each entry of the list shufflelist holds the current state and future states as files names. The method pop_batch loads in both image (img1, img2) and adds them to a batch list which is finally returned. The entries of the list are used for training the neural network model. The method push_batch is doing the opposite. It adds a batch list to the end of the list shufflelist.
We are now moving to the next method get_X. It prepares the batch list for training the neural network. The images (current state indicated by 0 and future state indicated by 3) in the batch list are converted to a numpy array and normalized with division by 255.0.
The method backprop does the training on the neural network. Its code was basically taken from the keras site. It also shows the Bellman equation which is handled in the deep reinforcement learning theory. In short, it predicts the future rewards with the model_target (future_rewards) with the future states (Xf). It uses the Bellman equation to calculate the new Q states (updated_q_values) to be trained into model. Finally it calculates the loss value (loss) which is needed to train the model with the current batch list (X).
The Game‘s method train is simply a wrapper. It pulls with method pop_batch a batch list. The current and future images (imgresh1, imgresh2) are saved to disk (write) and added to the batch list, so the batch list size is increased by one (so the batch list size is not 19 but 20 now). Then it trains the model with the method backprop, and pushes back the batch list to the shufflelist.
class Game:
# constructur and initialize, see above
# run, game_over, get_direction, get_maxi, see above
def load_replay_memory(self):
f = open(os.path.join(os.path.join(pathname, datadirname, datacsvname)), "r")
df = pd.read_csv(f, index_col = 0)
for index, row in df.iterrows():
currentpicname = row["currentstate"]
action = actionstonum[row["action"]]
reward = row["reward"]
nextpicname = row["nextstate"]
terminated = row["terminated"]
sxpos = row["sxpos"]
sypos = row["sypos"]
fxpos = row["fxpos"]
fypos = row["fypos"]
self.shufflelist.append([currentpicname,action,reward,nextpicname, terminated, sxpos, sypos, fxpos, fypos])
random.shuffle(self.shufflelist)
f.close()
return
def save_replay_memory(self):
data = []
if len(self.shufflelist) == 0:
return
if len(self.shufflelist) > self.REPLAYSIZE:
self.numbatches = len(self.shufflelist) - self.REPLAYSIZE
self.overall_numbatches += self.numbatches
for i in range(len(self.shufflelist) - self.REPLAYSIZE):
item = self.shufflelist.pop(0)
os.remove(os.path.join(self.path,item[0]))
os.remove(os.path.join(self.path,item[3]))
for (cs, act, rew, fs, term, sx, sy, fx, fy) in self.shufflelist:
data.append({'currentstate': cs, 'action': numtoactions[act], 'reward': rew, 'nextstate': fs, 'terminated': term, 'sxpos': sx, 'sypos': sy, 'fxpos': fx, 'fypos': fy})
df = pd.DataFrame(data)
df.to_csv(os.path.join(self.path, datacsvname))
return
def pop_batch(self, batchsize):
batch = []
files = []
for i in range(batchsize):
item = self.shufflelist.pop(0)
img1 = cv2.imread(os.path.join(self.path, item[0]),cv2.IMREAD_COLOR )
img2 = cv2.imread(os.path.join(self.path, item[3]),cv2.IMREAD_COLOR )
batch.append([img1, item[1], item[2], img2, item[4], item[5], item[6], item[7], item[8]])
files.append((item[0],item[3]))
return batch, files
def push_batch(self, batch, files):
for index,item in enumerate(batch):
self.shufflelist.append([files[index][0], item[1], item[2], files[index][1], item[4], item[5], item[6], item[7], item[8]])
return
def get_X(self, batch, state):
assert state == 0 or state == 3 # 0 is currentstate, 3 is future state
X = [item[state] for item in batch]
X = np.array(X, dtype=np.float32)
X /= 255.0
return X
def backprop(self, batch):
rewards_sample = [batch[i][2] for i in range(len(batch))]
action_sample = [batch[i][1] for i in range(len(batch))]
done_sample = tf.convert_to_tensor([float(batch[i][4]) for i in range(len(batch))])
X = self.get_X(batch, 0)
Xf = self.get_X(batch, 3)
future_rewards = self.model_target.predict(Xf)
updated_q_values = rewards_sample + 0.99 * tf.reduce_max(future_rewards, axis=1)
updated_q_values = updated_q_values * (1 - done_sample) - done_sample*abs(self.PENALTY)
masks = tf.one_hot(action_sample, 4)
with tf.GradientTape() as tape:
q_values = self.model(X)
q_action = tf.reduce_sum(tf.multiply(q_values, masks), axis=1)
loss = self.loss_function(updated_q_values, q_action)
grads = tape.gradient(loss, self.model.trainable_variables)
self.optimizer.apply_gradients(zip(grads, self.model.trainable_variables))
def train(self, i, j, term):
# https://pythonprogramming.net/training-deep-q-learning-dqn-reinforcement-learning-python-tutorial/
currentstate = "current_{}_{}.png".format(i,j)
nextstate = "next_{}_{}.png".format(i,j)
batch, files = self.pop_batch(self.BATCHSIZE)
batch.append([self.imgresh1, actionstonum[self.changeto], self.reward, self.imgresh2, term, self.snake_pos[0], self.snake_pos[1], self.food_pos[0], self.food_pos[1]])
files.append(("current_{}_{}.png".format(i,j), "next_{}_{}.png".format(i,j)))
self.write(i,j)
self.backprop(batch)
self.numbatches += 1
self.push_batch(batch, files)
return
The remaining methods of Game are utility methods. The first utility method is print_benchmark. After training models, we needed some kind of indication if the training went into a positive direction or into a negative direction. With the method print_benchmark we get this indication. In the method print_benchmark we first create two lists: maxlist and penaltylist. The list maxlist contains all states where the snake ate food. The list penaltylist contains all states where the snake went into the window frame border or into its own body. Secondly we are testing the trained model with the content of maxlist and penaltylist and check if the predictions are correct. In case of incorrect predictions a statistical value pmerror is updated, which indicates how often the model predicts a move of the snake towards the food position wrongly. So ideally this value must be zero. The value pterror indicates how often the snake will go into a termination state. This number should be ideally zero as well. Other benchmarks are the averaged Q states. These are very important to consider, because they should not explode and converge to the same number.
The methods print_score and print_overall_score print out the score of the current game or the score of a large set of games. Scores can also be used as benchmarks.
After all, we have the method run_replay_memory. It loads in the complete replay data into the list shufflelist and runs the method backprop on the content of shufflelist. Here is no need to use method run to train the model. However we still need the method run to generate more training data and refresh the replay memory.
def class Game:
# constructur and initializer, see above
# run, game_over, get_direction, get_maxi, see above
# load_replay_memory, save_replay_memory, pop_batch, push_batch, get_X, backprop, train, see above
def print_benchmark(self):
maxlist = []
penaltylist = []
averagestates = [0,0,0,0]
averagepenalty = [0,0,0,0]
pmerror = 0
pterror = 0
for (cs, act, rew, fs, term, sx, sy, fx, fy) in self.shufflelist:
if rew == self.MAXREWARD or rew == 30.0:
maxlist.append((cs,act,rew,fs,term))
if rew == self.PENALTY:
penaltylist.append((cs,act,rew,fs,term))
print(f"Number of maxrewards in shufflelist: {len(maxlist)}, perc: {100*len(maxlist)/len(self.shufflelist)}")
print(f"Number of terminations in shufflelist: {len(penaltylist)}, perc: {100*len(penaltylist)/len(self.shufflelist)}")
count = 0
print("Testing maxlist")
for i in range(len(maxlist)):
img = cv2.imread(os.path.join(pathname, datadirname, maxlist[i][0]),cv2.IMREAD_COLOR )
states = self.model.predict(np.array([img])/255.0, batch_size=1, verbose=0)[0]
averagestates += states
if np.argmax(states) != maxlist[i][1]:
count += 1
pmerror = 100*count/len(maxlist)
print(f"Number of predicted errors in maxlist: {count}, perc: {pmerror}")
print(f"Q Values for max: {averagestates/len(maxlist)}")
count = 0
print("Testing penaltylist")
for i in range(len(penaltylist)):
img = cv2.imread(os.path.join(pathname, datadirname, penaltylist[i][0]),cv2.IMREAD_COLOR )
states = self.model.predict(np.array([img])/255.0, batch_size=1, verbose=0)[0]
averagepenalty += states
if np.argmax(states) == penaltylist[i][1]:
count += 1
pterror = 100*count/len(penaltylist)
print(f"Number of predicted terminations in penaltylist: {count}, perc: {pterror}")
print(f"Q Values for penalty: {averagepenalty/len(penaltylist)}")
return pmerror, averagestates/len(maxlist), averagepenalty/len(penaltylist)
def print_score(self):
print(f" ----> TIME IS {datetime.now():%Y-%m-%d_%H-%M-%S}")
print(f" ----> SCORE is {self.score}")
print(f" ----> NUM OF BATCHES is {self.numbatches}")
return self.score, self.numbatches
def print_overall_score(self):
print(f"--> TIME IS {datetime.now():%Y-%m-%d_%H-%M-%S}")
print(f"--> OVERALL SCORE is {self.overall_score}")
print(f"--> OVERALL NUM OF BATCHES is {self.overall_numbatches}")
return self.overall_score, self.overall_numbatches
def run_replay_memory(self, epochs = 5):
self.model.load_weights(self.checkpointname)
self.load_replay_memory()
for j in range(epochs):
for i in range(int(len(self.shufflelist)//(self.BATCHSIZE+1))):
if i%500 == 0:
print(i)
batch, files = self.pop_batch(self.BATCHSIZE+1)
self.backprop(batch)
self.push_batch(batch,files)
self.print_benchmark()
self.save_checkpoint()
The class Game has been need sufficiently explained now. Below the code to execute instances of Game to generate training data and to train the model. In the code below the function run_game instantiates Game several times (range(iterations)) within a loop with a given learning rate as a parameter. In a underlying loop it initializes and runs instances of Game with initialize and run and prints the benchmark with print_benchmark. In case there is an improvement concerning one of the benchmarks, a checkpoint of the model is saved. During the iterations the list shufflelist is saved back to disk with the method save_replay_memory.
def run_game(learning_rate = 1.5e-06, epochs = 5, benchmin = 68.0):
manual = False
lr = [learning_rate for i in range(epochs)]
iterations = len(lr)
benches = []
qms = []
qps = []
counter = 0
for i in range(iterations):
print(f"{i}: learning rate: {lr[i]}")
game = Game(lr[i], "model-regr.h5")
k = 150
game.load_replay_memory()
for j in range(k):
game.initialize(i, j)
game.run(j)
bench, qm, qp = game.print_benchmark()
benches.append(bench)
qms.append(qm)
qps.append(qp)
game.save_replay_memory()
game.save_checkpoint(f"model-regr_{i}_{lr[i]:.9f}_{bench:.2f}.h5")
if bench < benchmin:
benchmin = bench
game.save_checkpoint()
else:
counter += 1
if counter == 3:
counter = 0
lr *= 0.5
overallscore = game.print_overall_score()
overallscores.append(overallscore)
return benches, qms, qps
Executing the code
The function run_game can be executed like shown in the code below. Parameters are learning rate, epochs and benchmark threshold.
run_game(1.5e-06, 5, 60.0)
To run training on the complete replay memory we execute the code below. The first parameter of the Game class is the learning rate, the second parameter is the name of the checkpoint with the neural networks weights to be updated. The method run_replay_memory trains the neural network with a number of epochs. In this case it is five.
game = Game(6.0e-07, "model-regr.h5") game.run_replay_memory(5)
The function run_game and the method run_replay_memory both execute print_benchmark. It prints out an indication how successful the training was. Below you find an output of print_benchmark. It shows how many times the snake eats food (maxrewards) and how many terminations we find in the replay memory . The lists maxlist and penaltylist (see description of print_benchmark) are used to indicate how well the model predicts the eating of food and terminations. In the example below you find that the eating of food are 51% of all cases badly predicted and terminations are 41% of all cases badly predicted. The print below shows averaged values of the Q states for each action (RIGHT, LEFT, UP, DOWN). Ideally they should contain numbers in a close range. You can interpret a Q state in such a way: If you take an action RIGHT, the reward will be in future 0.51453086. This number should go up while training, but also as its limits. The score of the snake game will always be finite, because the snake grows larger each time it eats food. The limit is indirectly given by the size of the frame window. Important to know is, that the Q states of each action must be on average the same number, because statistically you must always get the same reward if the snake goes in either direction.
Number of maxrewards in shufflelist: 2783, perc: 6.9575 Number of terminations in shufflelist: 2042, perc: 5.105 Testing maxlist Number of predicted errors in maxlist: 1437, perc: 51.63492633848365 Q Values for max: [0.51453086 0.5192453 0.50427304 0.48402 ] Testing penaltylist Number of predicted terminations in penaltylist: 856, perc: 41.9196865817 Q Values for penalty: [0.21559233 0.16576494 0.22125778 0.210446 ] saving checkpoint: /home/inf/Dokumente/Reinforcement/model/model-regr.h5
Conclusion
We have run the code for days (in specific run_game and run_replay_memory) and tried with modifying the hyper parameters. During the run we produced millions of frames. In general we set the EPSILON value first to 0.3. This means that about 30% of the moves went to the direction of the food with the help of Game‘s method get_direction. The remaining moves were predicted by the model.
We were able to see that all average Q state values in maxlist of printed out by print_benchmark went above 1.6. This matches our observations that the number of scores went to around 270 after playing 150 games.
After running the game further we set the EPSILON value to 0.2, so more predictions were made by the game. Now the overall score went down. This time we made 100 scores after playing 150 games. You were able to see how the average Q state values went down after some time.
On the keras site, there is a note, that it takes 50 million frames to receive very good results. However at some point of time we stopped experimenting anything further. We were seeing that progress is extremely slow or none existent. We are inclined to say, that other methods but deep reinforcement learning are more promising. Despite the simpleness of the snake game, which is comparable to atari games, we were a little discouraged after reading [2].
Outlook
Applied research must give a solution for problems for a programmer who wants to develop an application. So the programmer must get some benefit from it. However we find that there are too many hyper parameters to turn (size of replay memory, learning rate, batch size, EPSILON value, DISCOUNT value, dimension of status images, the list does not end here) and progress is still extremely slow or not existent. A programmer wants to have results within a defined period of time. We have the feeling we do not have the development time under control with deep reinforcement learning.
Maybe there was just not enough training time for experimentation. Maybe the model with its five layers is not appropriate and needs fine tuning. Anyway, we think that other ways of machine learning (supervised learning) are much more successful than deep reinforcement learning.
We are thinking about estimating the head position and food position with a trained neural network by giving an image of the window frame. Then we calculate the moving direction for the snake. In the code above we actually record the head and food position and save it into the replay memory’s csv file for each current state and future state. So this information comes for free. Small experiments showed that the head and food position can be predicted very well with the same neural network model (instead of Q states we estimate positions of snake head and food).
Anyway, we have not completely given it up, but we just put a break in here. So there might come more in future.
Acknowledgement
Special thanks to the University of Applied Science Albstadt-Sigmaringen for providing the infrastructure and the appliances to enable this research
References
[1]: Playing Atari with Deep Reinforcement Learning, Volodymyr Mnih et. al.
[2]: Deep Reinforcement Learning Doesn’t Work Yet
[3]: Deep Q-Learning for Atari Breakout
[4]: Snake Game.py